TAPIR
Overview
TAPIR [1] is a visualization software for chromatographic data obtained by mass spectrometry. It provides efficient visualization of high-throughput targeted proteomics experiments.
The TAPIR software is a fast and efficient Python visualization software for chromatograms and peaks identified in targeted proteomics experiments. The input formats are open, community-driven standardized data formats (mzML for raw data storage and TraML encoding the hierarchical relationships between transitions, peptides and proteins).
TAPIR is scalable to proteome-wide targeted proteomics studies (as enabled by SWATH-MS), allowing researchers to visualize high-throughput datasets. The framework integrates well with existing automated analysis pipelines and can be extended beyond targeted proteomics to other types of analyses.
Contact and Support
We provide support for TAPIR on the GitHub repository through GitHub issues or you can contact the author Hannes Röst.
Installation
You can download binaries from here (Mac OSX and 64 bit Microsoft Windows). The source code is available from Github which allows source-based installation. Please follow the instructions found there for manual installation or installation on a Linux system.
Note: for a successfull installation on Mac OS X, extract the provided file and drag it into the Applications folder. You may need to allow execution of the software if you see a warning that TAPIR is from an “unidentified developer”. Simply go to System Preferences, click on “Security & Privacy” and in the “General” tab allow the execution of TAPIR.
Tutorial
The TAPIR software is highly flexible and interactive, allowing for investigation of single data traces and data points. Each graph item can be selected and inspected individually, allowing for customization of the visualization and production of publication-quality figures. Data can be exported as an image or in table format and used for further analysis; individual traces can be removed or re-added and all graph settings (such as color, line width, line style etc.) are fully customizable. The implementation relies on guiqwt for these features.
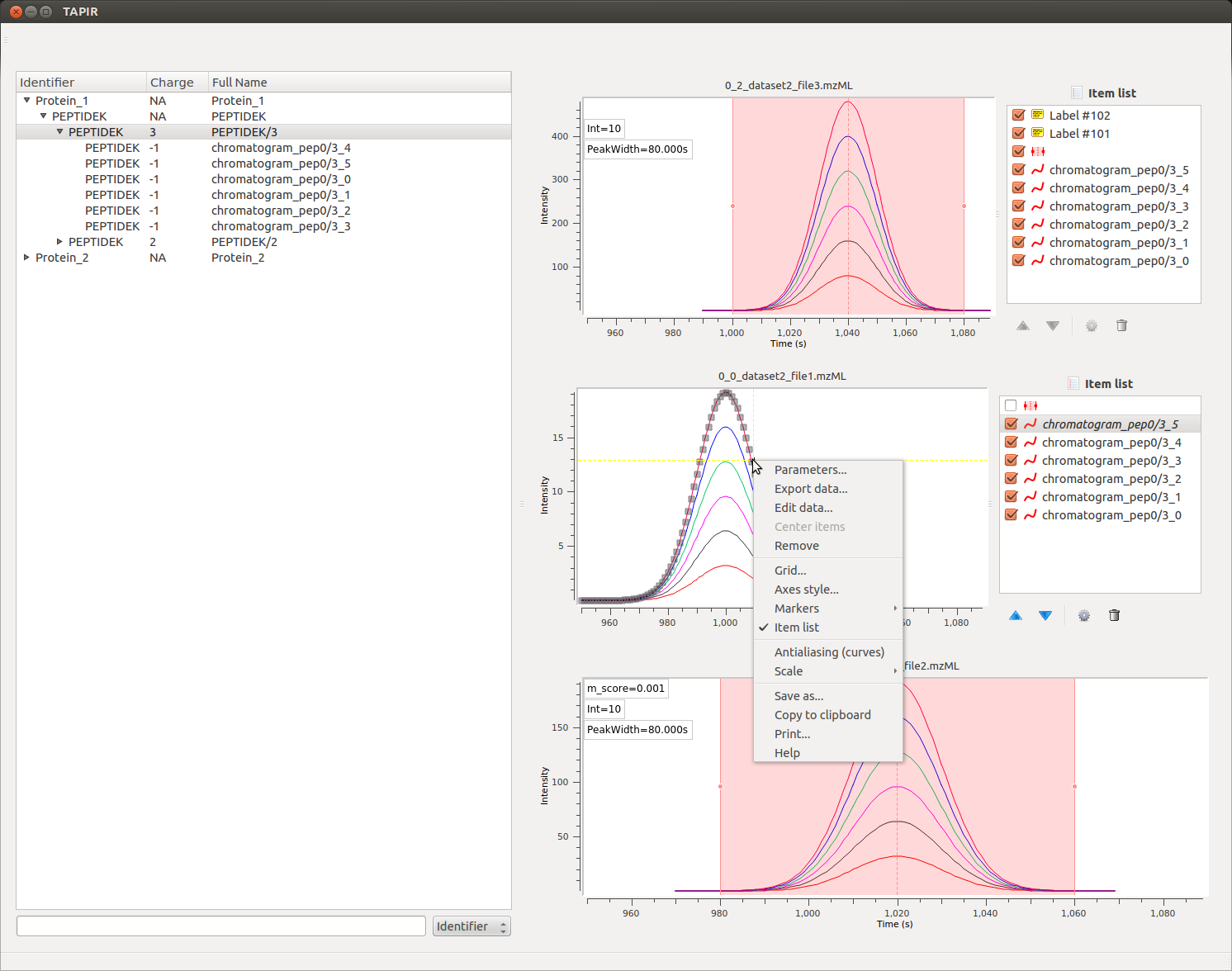
Data
Availability
You can download a small sample dataset. A larger, real-life dataset can be obtained by downloading these five files (this might take a while since the whole dataset is ca 5 GB)
This dataset is retrieved from the original OpenSWATH publication [2] and the two conditions (0% and 10%) refer to the treatment of S. pyogenes with human plasma. For each condition, two biological replicates are available.